Веб-скрапинг — это метод сбора данных с веб-сайтов. Этот термин обычно используется в применении к автоматизированному сбору данных. Сегодня мы поговорим о том, как собирать данные с сайтов анонимно. Причина, по которой некто может захотеть анонимности в деле веб-скрапинга, заключается в том, что многие веб-серверы применяют определённые правила к подключениям с IP-адресов, с которых за некий отрезок времени выполнено какое-то количество запросов. Здесь мы будем пользоваться следующими инструментами:
Надо отметить, что правовые аспекты веб-скрапинга — вопрос непростой и часто неясный. Поэтому уважайте «Условия использования» тех страниц, данные которых вы собираете. Вот хороший материал на эту тему.

Установка Tor
Начнём с начала — поэтому первым делом установим клиент Tor, воспользовавшись следующей командой:
sudo apt-get install tor
Настройка Tor
Теперь настроим клиент Tor. В конфигурации Tor, применяемой по умолчанию, используется порт SOCKS, который даёт нам один путь к единственному выходному узлу (то есть — один IP-адрес). Для повседневного использования Tor, вроде обычного просмотра веб-страниц, это вполне подходит. Но нам нужно несколько IP-адресов. Это позволит переключаться между ними в процессе веб-скрапинга.
Для того чтобы настроить Tor так, как нам нужно, мы просто откроем дополнительные порты для прослушивания SOCKS-соединений. Делается это путём добавления нескольких записей SocksPort в главный конфигурационный файл программы, который можно найти по адресу /etc/tor.
Откроем файл /etc/tor/torrc с помощью какого-нибудь текстового редактора и добавим в конец файла следующие записи:
# Откроем 4 SOCKS-порта, каждый из которых даёт нам новый Tor-маршрут. SocksPort 9050 SocksPort 9052 SocksPort 9053 SocksPort 9054
Тут стоит обратить внимание на следующее:
- Значение каждого параметра
SocksPortявляется числом. Число — это номер порта, по которому клиент ожидает поступления соединения от приложений, использующих протокол SOCKS, вроде браузеров. - Так как значение
SocksPortзадаёт порт, который будет открыт, порт с соответствующим номером должен быть свободным, а не используемым каким-нибудь другим процессом. - Номера портов начинаются с
5050— номера порта, используемого Tor-клиентом по умолчанию. - Мы пропустили номер порта
5051. Этот порт используется Tor для того, чтобы позволить внешним приложениям, подключающимся по данному порту, управлять процессом Tor. - Выбирая номера портов после
5051, мы пользуемся простым соглашением, в соответствии с которым номера портов увеличиваются на 1.
Для того чтобы применить изменения, внесённые в конфигурационный файл, перезапустим клиент Tor:
sudo /etc/init.d/tor restart
Создание нового проекта Node.js
Создадим новую директорию для проекта. Назовём её superWebScraping:
mkdir superWebScraping
Перейдём в эту директорию и инициализируем пустой Node-проект:
cd superWebScraping && npm init -y
Установим необходимые зависимости:
npm i --save puppeteer cheerio
Работа с веб-сайтами с помощью Puppeteer
Puppeteer — это браузер без пользовательского интерфейса, который использует протокол DevTools для взаимодействия с Chrome или Chromium. Причина, по которой мы не используем тут библиотеку для работы с запросами, вроде tor-request, заключается в том, что подобная библиотека не сможет обрабатывать сайты, созданные в виде одностраничных веб-приложений, содержимое которых загружается динамически.
Создадим файл index.js и поместим в него следующий код. Основные особенности этого кода описаны в комментариях.
/** * Подключим библиотеку puppeteer. */ const puppeteer = require('puppeteer'); /** * В функции main размещаем код, который * будет использован в ходе веб-скрапинга. * Причина, по который мы создаём асинхронную функцию, * заключаемся в том, что мы хотим воспользоваться асинхронными * возможностями puppeteer. */ async function main() { /** * Запускаем Chromium. Установив ключ `headless` в значение false, * мы можем видеть интерфейс браузера. */ const browser = await puppeteer.launch({ headless: false }); /** * Создаём новую страницу. */ const page = await browser.newPage(); /** * Используя новую страницу, переходим на https://api.ipify.org. */ await page.goto('https://api.ipify.org'); /** * Ждём 3 секунды и закрываем экземпляр браузера. */ setTimeout(() => { browser.close(); }, 3000); } /** * Запускаем скрипт, вызвав main(). */ main();
Запустим скрипт следующей командой:
node index.js
После этого на экране должно появиться окно браузера Chromium, в котором открыт адрес https://api.ipify.org.
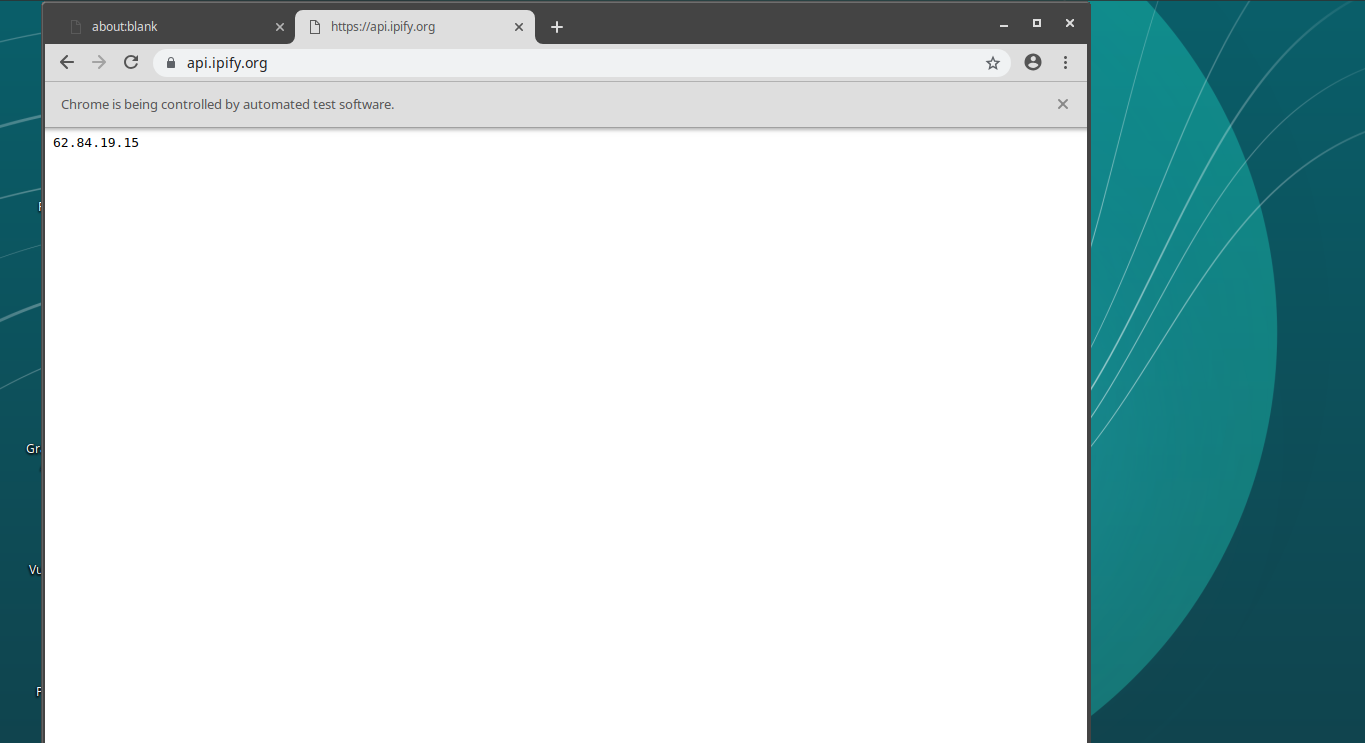
Окно браузера, Tor-подключение не используется
Я открыл в окне браузера именно https://api.ipify.org из-за того, что эта страница может показать общедоступный IP-адрес, с которого к ней обращаются. Это — тот адрес, который виден посещаемым мной сайтам в том случае, если я захожу на них без использования Tor.
Изменим вышеописанный код, добавив следующий ключ в объект с параметрами, который передаётся puppeteer.launch:
/** * Запускаем Chromium. Установив ключ `headless` значение false, * мы можем видеть интерфейс браузера. */ const browser = await puppeteer.launch({ headless: false, // Добавим следующую строку. args: ['--proxy-server=socks5://127.0.0.1:9050'] });
Мы передали браузеру аргумент --proxy-server. Значение этого аргумента сообщает браузеру о том, что он должен использовать socks5-прокси сервер, работающий на нашем компьютере и доступный на порте 9050. Номер порта является одним из тех номеров, которые мы до этого внесли в файл torrc.
Снова запустим скрипт:
node index.js
В этот раз на открытой странице можно будет увидеть другой IP-адрес. Это — тот адрес, который используется для просмотра сайта через сеть Tor.
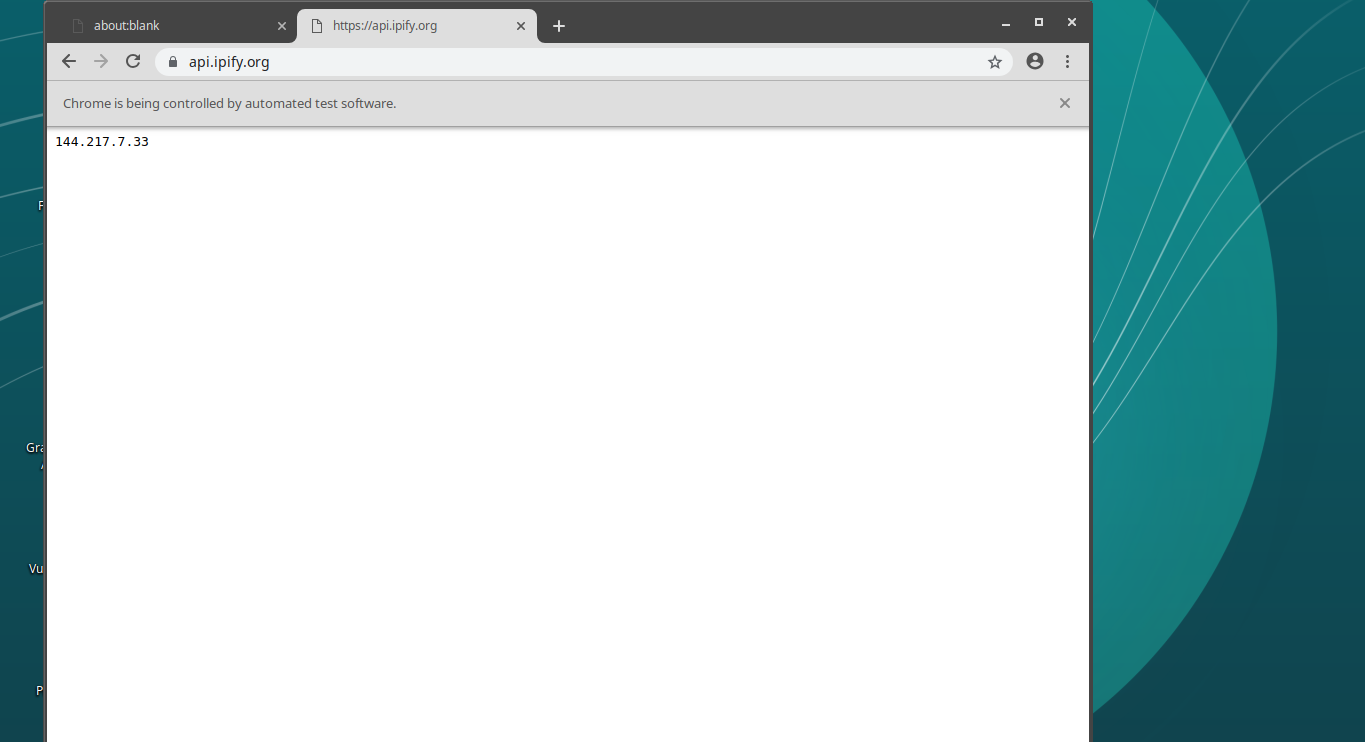
Окно браузера, Tor-подключение используется
В моём случае в данном окне появился адрес 144.217.7.33. У вас это может быть какой-нибудь другой адрес. Обратите внимание на то, что если вы снова запустите скрипт и используете тот же номер порта (9050), то вы получите тот же IP-адрес, что получали до этого.
Окно повторно запущенного браузера, Tor-подключение используется
Именно поэтому в настройках Tor мы открыли несколько портов. Попробуйте подключить браузер к другому порту. Это приведёт к изменению IP-адреса.
Сбор данных с помощью Cheerio
Теперь, когда в нашем распоряжении имеется удобный механизм загрузки страниц, пришло время заняться веб-скрапингом. Для этого мы собираемся воспользоваться библиотекой cheerio. Это — HTML-парсер, API которого устроено так же, как API jQuery. Наша задача заключается в том, чтобы взять со страницы Hacker News 5 заголовков самых свежих постов.
Перейдём на сайт Hacker News.
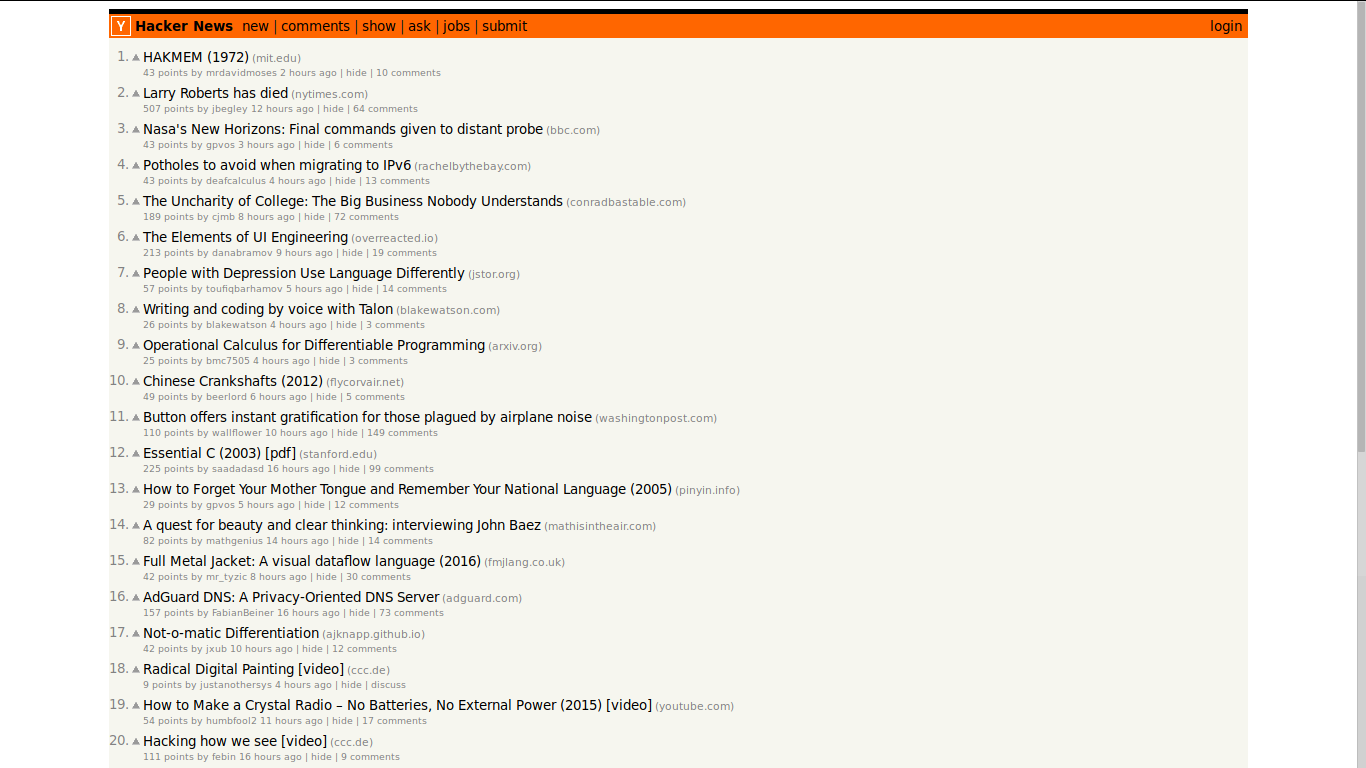
Сайт Hacker News
Мы хотим взять с открытой страницы 5 свежих заголовков (сейчас это «HAKMEM (1972)», «Larry Roberts has died» и другие). Исследуя заголовок статьи с помощью инструментов разработчика браузера, я заметил, что каждый заголовок помещён в HTML-элемент с классом storylink.
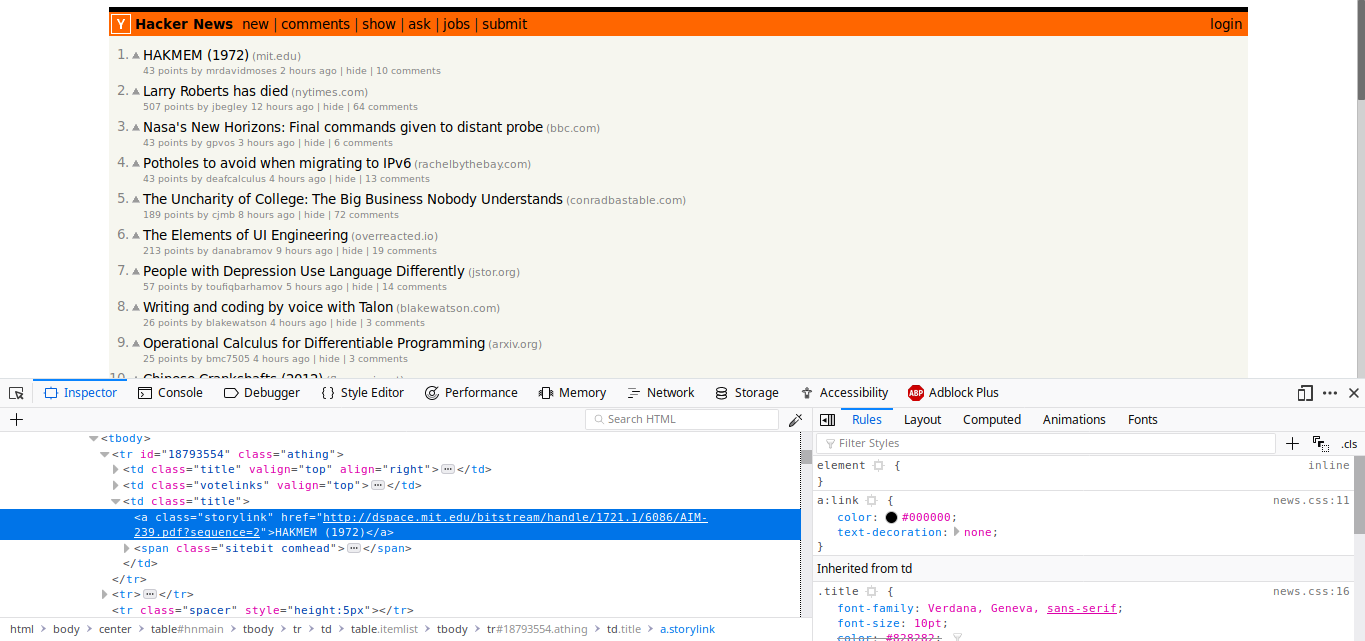
Исследование структуры документа
Для того чтобы извлечь из HTML-кода страницы то, что нам нужно, требуется выполнить следующую последовательность действий:
- Запуск нового экземпляра браузера без пользовательского интерфейса, подключённого к Tor-прокси.
- Создание новой страницы.
- Переход по адресу
https://news.ycombinator.com/. - Получение HTML-содержимого страницы.
- Загрузка HTML-содержимого страницы в
cheerio. - Создание массива для сохранения заголовков статей.
- Получение доступа к элементам с классом
storylink. - Получение первых 5 элементов с помощью метода
cheerioslice(). - Обход полученных элементов с использованием метода
cheerioeach(). - Запись каждого найденного заголовка в массив.
Вот код, реализующий эти действия:
const puppeteer = require('puppeteer'); /** * Подключим библиотеку cheerio. */ const cheerio = require('cheerio'); async function main() { const browser = await puppeteer.launch({ /** * Применим стандартный режим без пользовательского интерфейса (окно браузера не видно). */ headless: true, args: ['--proxy-server=socks5://127.0.0.1:9050'] }); const page = await browser.newPage(); await page.goto('https://news.ycombinator.com/'); /** * Получим содержимое страницы в виде HTML-кода. */ const content = await page.content(); /** * Загрузим код в cheerio. */ const $ = cheerio.load(content); /** * Создадим массив для хранения заголовков статей. */ const titles = []; /** * Работа с элементами, имеющими класс `storylink`. * Метод slice() используется для доступа только к 5 первым таким элементам. * Перебираем их с помощью метода each(). */ $('.storylink').slice(0, 5).each((idx, elem) => { /** * Получаем внутренний HTML-код, соответствующий тексту заголовка. */ const title = $(elem).text(); /** * Помещаем заголовок в массив. */ titles.push(title); }) browser.close(); /** * Выводим массив заголовков в консоль. */ console.log(titles); } main();
Вот что произойдёт после запуска этого скрипта.
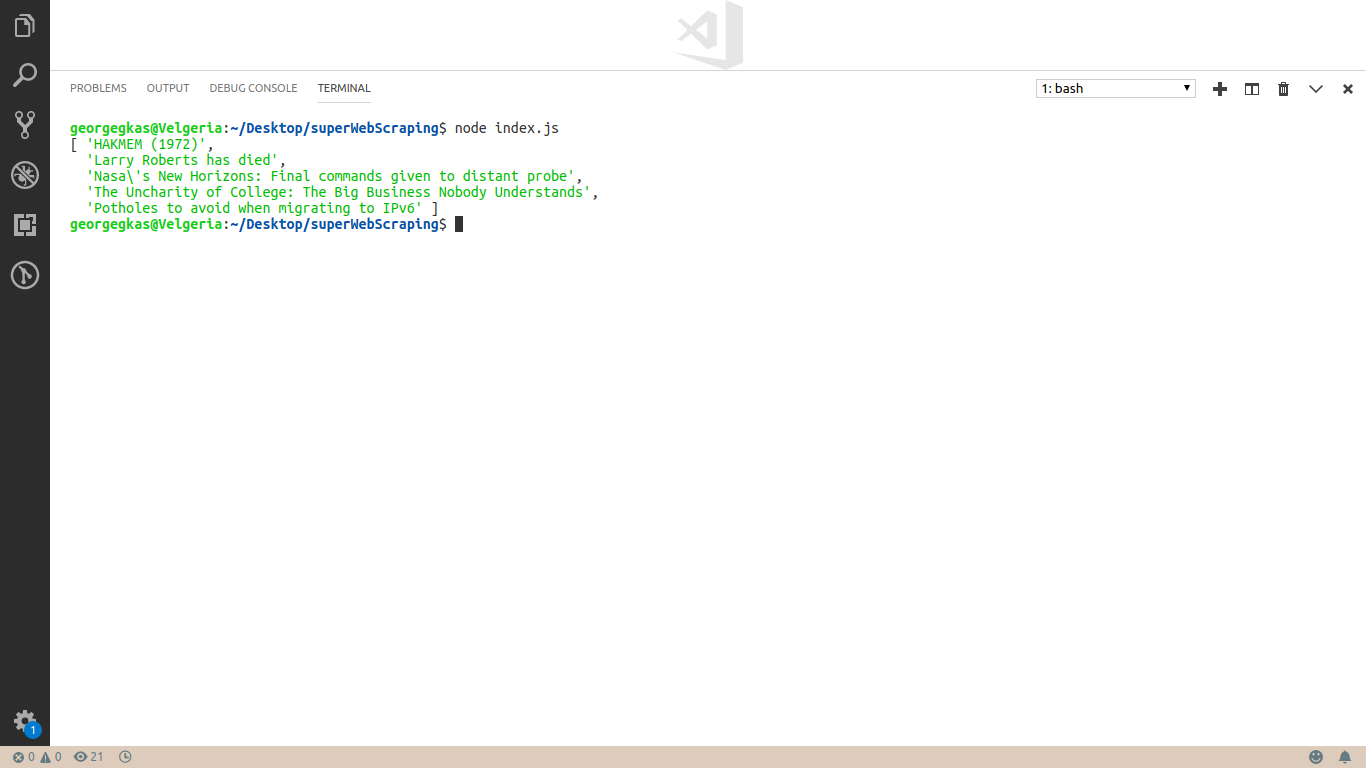
Первые 5 заголовков с Hacker News успешно извлечены из кода страницы
Непрерывный скрапинг с использованием разных IP-адресов
Теперь поговорим о том, как воспользоваться различными SOCKS-портами, которые мы задали в файле torrc. Это довольно просто. Мы объявим массив, в каждом из элементов которого будет содержаться номер порта. Затем переименуем функцию main() в функцию scrape() и объявим новую функцию main(), которая будет вызывать функцию scrape(), передавая ей при каждом вызове новый номер порта.
Вот готовый код:
const puppeteer = require('puppeteer'); const cheerio = require('cheerio'); async function scrape(port) { const browser = await puppeteer.launch({ args: ['--proxy-server=socks5://127.0.0.1:' + port] }); const page = await browser.newPage(); await page.goto('https://news.ycombinator.com/'); const content = await page.content(); const $ = cheerio.load(content); const titles = []; $('.storylink').slice(0, 5).each((idx, elem) => { const title = $(elem).text(); titles.push(title); }); browser.close(); return titles; } async function main() { /** * Номера SOCKS-портов Tor, заданные в файле torrc. */ const ports = [ '9050', '9052', '9053', '9054' ]; /** * Вечный веб-скрапинг... */ while (true) { for (const port of ports) { /** * ...каждый раз - с новым номером порта. */ console.log(await scrape(port)); } } } main();
Итоги
Теперь в вашем распоряжении есть инструменты, которые позволяют заниматься анонимным веб-скрапингом.
Уважаемые читатели! Приходилось ли вам заниматься веб-скрапингом? Если да — просим рассказать о том, какие инструменты вы для этого используете.
